캐시- 리버스 프록시 캐시
로컬 캐시
글로벌 캐시
Local cache 짜줘
필요한 기능은 set, get, purge, LRU, LFU 기능이야
Next’s
SSR
이 부분에 관해서 성능테스트를 딱 진행했는데
트래픽이 확올라가다가 우수수수 떨어졌음
17TPS 정도 나와서
이걸 어떻게 해야되나? 싶었는데
어 캐시를 써
캐시 및 로드 밸런싱
캐시를 이용해서 대용량 트래픽을 대응하는 방법에 대해 설명하겠습니다

어디가 가장 속도가 느릴까?

이 부분이 속도가 가장 느림
왜 느릴까?
데이터 베이스 쪽에는
- 데이터에 접근 하는 시간이 오래 걸림
- Network, Disk IO
API 호출하는 부분에는
1. 외부 API 로직 실행, 인프라 연동
- API 호출해야 되는 콜을 받는 쪽은 또 Netowork, DIsk IO가 들어가 이중으로 사용됨
그래서 캐시를 사용할 수 밖에 없음
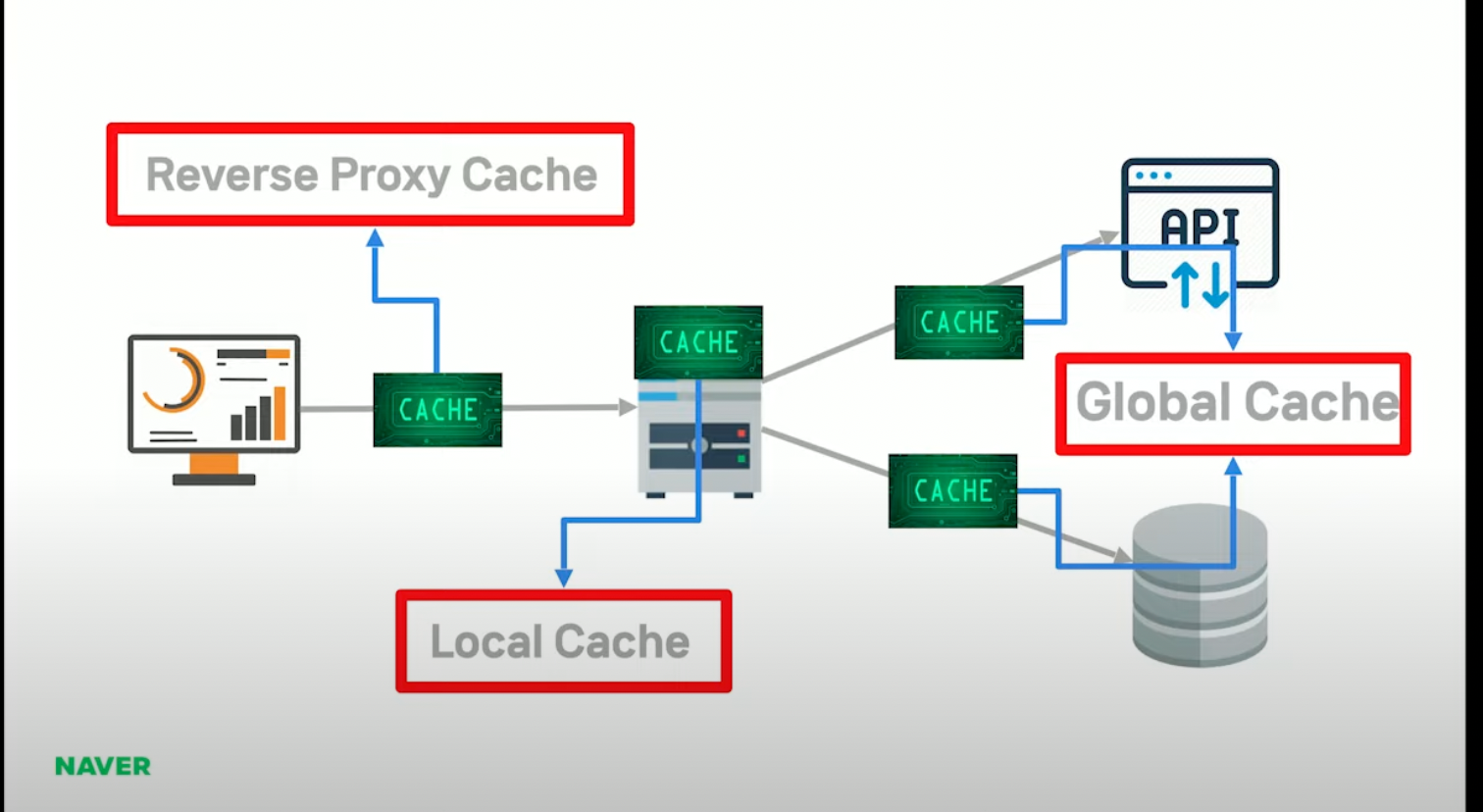
이 부분에 캐시를 사용할 수 있는데 캐시마다 명칭이 다름
클라이언트와 웹서버 사이에 있는 주로 proxy 서버들이 있는데
nginx라든지 배니시라든지 얘네들을 주로 리버스 프록시라 하고 얘네들을 다 캐시를 적용할 수 있음
그리고 어플리케이션에서 쓰는 캐시가 로컬 캐시고
나머지는 글로벌 캐시라고 흔히 아는 레디스, 맴캐시드등이 여기 해당 됨
클라이언트에 가까울 수 록 성능이 좋음.
당연히 네트워크 자원등을 아낄 수 있기 때문
미리 처리한 결과를 저장해서 사용하는 것.
메모리나 디스크를 저장소로 사용
기본적으로 nginx , 리버스 프록시의 경우 디스크에 저장함
메모리에 저장하는 이유는 빠르니까
그럼 메모리에 다 때려넣으면 되겠네?
싶겠지만 비쌈.
부자들은 가능할 수도.
캐시할 대상을 생각을 좀 해보면… 아무거나 다 넣을 수는 없음
주로 DataSource Json과
SSR 결과인 Html
렌더하는 시간이 꽤 걸림
어떤 연산을 많이 사용하느냐
READ 연산이 80% 이상
컨텐츠가 한번 캐시되면 바꿀일이 많이 없다는 뜻
캐시히트가 중요하기 때문에 70퍼센트 이하인건 사용하지 않는게 좋음
- 프로세서가 요청하는 데이터 중에서 캐시에 있는 데이터를 찾아낸다면 그것은 캐시 히트라고 부릅니다.
근데 한번 생각을 해봐야하는게
html에 json 같이 들어가서 수백KB인데, 심하면 메가단위로 올라가는데
이게 네트워크를 따라서 왔다갔다 한다?
redis는 싱글 스레드로 동작하는데
롱텀 메모리로 동작하면 좋지는 않음
밈캐시와 다르게 메모리를 계속할당하는데 이게 해결됐는지는 모르겠는데
그래서 파편화 이슈도 있는데
잡다한 기능 다들어있는데 굳이 쓸필요있는가?
오버엔지니어링
오버엔지니어링을 저는 경계함
최소한으로 시작해서 점점늘려가는 것을 보고 있음
거기에 민감해서 굳이 필요한가 생각을 함
전사 인프라 장애시
대응을 할 수가 없음, 우리는 안죽었었어요 우리는 메모리 캐시를 독립적으로 구축했어요
라는 방법도 필요함
퇴사할때도 인프라가 적은 게 인수인계에 유리
옛날에는 데이터를 저장할때 데이터를 메모리에 올리려 노력하고
주로 사용하는 중소기업 RDB는 MySQL
부자들은 Oracle이나 SQL Server를 사용함
SQL 서버가 제공하는 놀라운 기능들이 있음
InnoDB엔진
메모리엔진
옛날엔 디비서버도 불안정했었음
JSON을 Disk에 올려서 사용했었으나 disk IO가 떡상함
그래서 메모리에 올려서 사용하는 걸 고민을 하는데
메모리에 올린다는 건 멤디스크를 사용한다는 거고 멤디스크 솔루션을 사용해나 싶은데
찾아보니 리눅스에 /dev/shm 파티션에 올리면 shared memory 영역이라
멤디스크와 똑같은 결과를 얻을 수 있음
그다음에 이제 멤디스크에 올리면 파일을 올리고 쓰고 왔다갔다 해야되니까
파일이 왔다 갔다 해야 하니까
귀찮으니 로컬 캐시와 글로벌 캐시를 사용하자는 얘기가 나왔고 이건 요즘도 사용가능한 방법임
자바 개발자 분들은 Map 객체를 사용하면 쉽겠다고 생각할 수 있겠으나
아니요, 쉽지 않습니다.
주의해야 할 점이 있음.
Spring Bean안에 넣어서 우리는 보통 사용하는데
스레드 1,2,3이 캐시서비스를 호출하면 몇개 생길까요?
싱글턴이라 (스프링 빈객체가) 한개 생김
캐시 서비스에 맵 오프젝트가 있다고 치자,
스레드 1과 스레드 2에서 값을 똑같이 같고 오는데
스레드 2에서 먼저 일이 끝나고 값이 업데이트 됬음
그러면 스레드 1이 값을 또 업데이트하려 했을때 origin value가 이미 바뀌었있어
동시성 문제가 생김
자바에서는 이런 문제를 어떻게 해결하나?
Synchronized
Volatie
Atomic
값을 변경하려고 할때 Synchronized 거는건데
그러면 업데이트를 못하게 됨
근데 비용이 너무 비쌈
그다음 volatile이 있음
각각 코어에는 캐시메모리를 들고 있음
프로세서가 뭔가 실행할때
이 데이터를 메인 메모리에 올리게 됨
각각의 데이터들이 코어를 잡고 뭔가 실행을 하는데
그럼 각각의 데이터를 각자의 메모리에 업데이트를 함
스레드 1이 근데 먼저 끝나서 값을 업데이트 했어
스레드 2가 그다음에 완료하려고 하는데
캐시메모리에는 적용이 됐는데 메인 메모리에는 데이터가 다름.
이래서 또 동시성 문제가 발생함
이럴때 volatile을 쓰면 메인메모리에서 들고 오게됨
그러나 동시성 문제가 해결된 것은 아님
가시성은 확보할 수 있으나 다른 스레드에서도 메인메모리에 계속 쓰게 되므로
동시성은 확보할 수 없음
동시성을 확보하려면 readOnly 스레드와
Write Only스레드로 나누어서
읽는것은 여러개에서 해도
쓰는 것은 한곳에서 해야 동시성을 확보할 수 있음
마지막으로 atomic인데
concurrent.atomic 클래스가 자바에 있는데
CAS 카스 연산을 통해 동시성을 만족함
Compare And Swap임
말그대로 비교하고 할당한다임
값이 다른대서 업데이트 해서 바뀌었으면 업데이트하고 재시도
대부분은 크게 문제가 없겠지만
IT에서는 은탄환은 없다는 말을 많이 하는데
방금 같은 케이스에는 spin lock이 걸림
근데 스레드의 경우에는 락을 획득하지 못하면 컨텍스트 스위칭이 일어남
그 비용이 되게 크기 때문에
어떤 식으로 해결하냐, spin lock을 검
계속 루프를 거는 건데
최악의 상황에 계속 루프를 돈다면
계속 시도하다 어느정도 안되면 block 거는 방식으로 해결하는데
그래도 Synchronized 보단 빠름
이런 문제가 있다해도 .
ConcurrentHashMap에서는 CAS 연산을 지원함
그다음에는 block이라는 개념이 있는데
컨커런트 해시맵에는 Bucket이 기본 16개가 있는데
이 16개가 스레드가 정의할 수 있는 개수임
사로가 여러개 있는 것임
만약 이 버켓에 데이터가 들어 있어 그러면 Synchronized 걸어서 처리하고
빈 버킷의 경우에 CAS연산으로 인풋을 하는 방식의 concurrent Hashmap이
들어 있음
그다음에 SynchronizedMap이 패키지가 있긴 한데
ConcurrentHashMap과 성능 차이가 많이 나고 안쓰는게 좋음
ConcurrentHashMap을 자바에서 쓰면 다방면으로 사용할 수 있음
그런데 큰 문제가 있음
이건 서버 한대로 처리할 때의 이야기 임
처리량이 더 필요할 때 보통 스케일 업을 하잖아요
CPU를 올리고 뭐 저장공간을 올리고
그다음에 뭐 3대정도까지 늘릴 수 있겠죠
세대 정도까지늘리면 사실 수동으로라도 매치시켜줄 수 있어요
간단한 배치를 짠다든지
근데 컨테이너 환경에서 사용을 하잖아요
(쿠버네티스)
그러면 트래픽에 따라서 무한확장을 하는데
그때 문제가 됨
서버간 동기화 문제가 발생
이전에는 메모리가 문제가 됐다면 이제는 서버에도 동기화 문제가 발생
이때 Eventual consistency 방법으로 해결할 수 있음
- 데이터를 접근하는 것은 막지 않으면서,
- 리얼 타임이 아닌 니어리얼타임 언젠가에 consistency를 맞춰줄게 라는 이야기
동기화가 완료 될때 까지 접근을 막지 않고
Near Real Time Sync를 2초안으로 해서 맞춰줄게를 보장
그런데 이거 어떻게 하지?
배치를 짜볼까요?
귀찮네요
이때 스프링 클라우드 컨피그가 등장을 합니다.
스프링 클라우드 컨피그에 대해서는 블로그도 많고 챗지피티한테 물어보시면 될 것 같습니다.
-스프링 클라우드(Spring Cloud) 프로젝트의 일부로, 분산 시스템에서 마이크로서비스 아키텍처를 지원하기 위한 설정 관리 도구
스프링 클라우드는 설정을 깃에다 저장함
스프링 컨피그가 그걸 읽어서 처리하는데
스프링 부트 어플리케이션을 사용하려면
Bootstrap.properties를 사용해야하고
여기에 config server address가 들어감
디펜던시를 걸면 사용할 수 있는데
얘는 어플리케이션 properties보다 먼저 실행됨
그래서 그 특성을 이용해서
어플리케이션 뜰때 설정을 읽어서 뜬다고 보시면 될 것 같습니다.
그래서 특성을 정리하면
어플리케이션 실행 시 properties를 외부에 저장 가능
다중 컨테이너에서 동일한 환경으로 실행 가능
사실 이정도만 적용하고 안쓸거에요
그런데 너무나 매력적인 쓰는 포인트는 application을 재배포하지않고
properties를 적용할 수 있음.
배포하지 않고 프로퍼티를 적용할 수 있는데 2가지 방법이 있음
하나는 @RefreshScope라는 어노테이션을 써야하고
그다음에 이벤트 체인지를 구현하는 방법이 있음
배포없이 Post로 /refresh를 호출
근데 사전작업이 필요
- 설정파일을 수정하고
- GIT PUSH
- /refresh Post 호출
서버 세대이상이다 그러면 한대한대 마다 다 호출해 줘야함
귀찮잖아요
이때 spirng cloud bus가 나옴
얘는 메시지 브로커나 레디스를 사용할 수 있음.
Pub sub 패턴을 적용할 수 있다는 애기죠
아까랑 다른게 아까
우리가 메시지가 수정되면
Config 서버에 직접 찌른 것과 달리
스프링 부트 어플리케이션들은
카프카를 subscribe 하고 있는 거에요
아까랑 다른게 아까 메시지가 수정되면
Config 서버를 직접 찌른 것과 달리
스프링 부트 어플리케이션들은 카프카를 서브스크라이브 하고 있음
새로 뜬애도 마찬가지
컨피그 서버에 /busrefresh라는 것을 날려주면
어 갱신됐어
카프카에 그럼 데이터가 들어가게 되고
그럼 구독하고 있는 것들은 변경된 데이터를 받을 수 있게 됨
근데 쓰다 보니까 git push 하기가 귀찮음
자동으로 갱신해줘
설계를 변경
요청이 들어온 캐시가 존재하냐 아니냐에 따라 프로세스가 나뉨
캐시를 저장하는게 문제
Config 서버는 기본적으로
한 번의 수동 조작으로 설정을 여러 어플리케이션에 자동으로 적용하고
배포없이 수정사항을 적용하는 것인데
전제조건이 문제
설정을 git에서 clone 받고
수정을 하고 git 에 다시 push 한 이벤트가 발생
해야만 적용할수 가 있음
아직은 왜 미치겠는거지 와닿지 않을 수 있는데
아래와 같은 구조임

K8s pod단위라고 생각하면 됨
K8s는 보통 네트워크 스토리지를 사용함
클론 받은 데이터를 네트워크 스토리지에 써, 변경된 것을 수정을 해
Git에 커밋을 해 그다음에 refresh를 날려
이작업이 여러개 파드에서 동시다발적으로 일어나게 되는 것임
우리 개발 팀 내에서만 git써도 conflict나서 짜증나잖아요
안되겠다
답이 안나오네 라고 판단이 됐어요
또 network storage I/O문제나 Cache Sync 복잡도 문제도 있음
또 문제점이 하나 있는데 properties의 속성을 생각해 보면
HastTable을 구현한 구현체임
요즘은 잘안나오는 것 같은데 옛날에 자주 나왔던 면접질문으로
HashMap, HashTable 차이가 뭐야있음
그런 문제도 있고
애는 객체가 들어갈 수 있음
캐시를 대상으로 수천개가 들어가면 yaml파일인데 수도 없이 커질 수 있음
그럼 직접 넣지말고
Key Map만 따로 관리를 하자
Dynamic Key와 Static Key 를 나눠서 Map으로 합치자
Config Server는 트리거로만 쓰자
부연 설명 HashMap과 HashTable 모두 Map을 사용하는 구현체로
키-값을 저장하는 자료구조를 제공
그러나 차이점은
동기화에서
HashMap은 비동기적으로 동작하며 수정작업시 외부 동기화가 필요하나 성능
상 이점이 있고
HashTabel은 모든 메서드가 동기화되어 있어 여러 스레드간에 안전하지만
서능이 HashMap보다 떨어질 수 있음
요즘 버전에서는 ConcurrentHashMap과 같은 동시성을 사용하는 클래스를
고려할수 도 있음
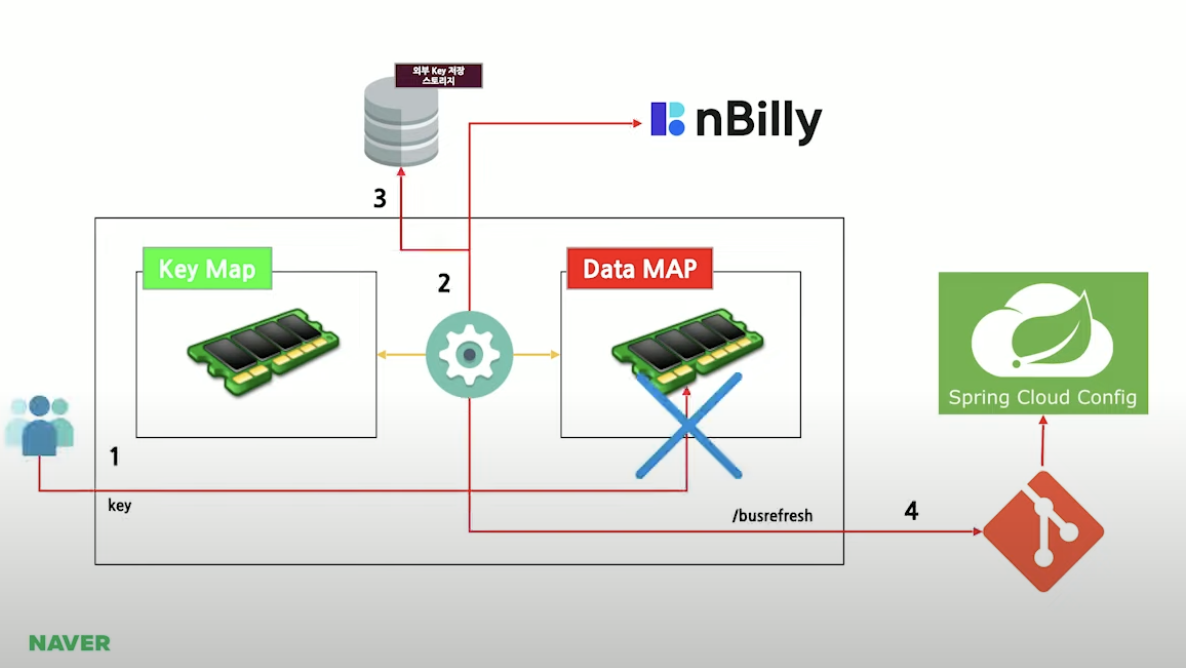
어플리케이션이 실행되면 제일 먼저 외부 저장 스토리지에서
키를 갖고오고
그 다음에 컨피그 서버에서 키를 가져와서 머지해가지고
오리진 서버에 요청에서 데이터를 가져와서 데이터를 바인딩 하는 것
그래서 새로 띄워진 파드는 데이터가 항상 갱신된 상태로 메모리에 올라가짐
(항상 최신의 데이터로)
유저가 요청을 했는데 하필 싱크가 안된 서버에 하필이면 요청을 했다면
그때 없잖아요 그럼 오리진 서버 갔다와서 아 이 데이터 이키야 오리진 스토어에 저장하고 키맵에서 저장되고 이파드는 로직 흘러가고
새로운 키 저장됐어 라고 스프링 클라우드 컨피그 쪽에다가 버스 날려서 이벤트를
발행해주는 것
그럼 모든 파드에서 어 새로운 데이터 들어왔네 하고 싱크를 맞추겠죠
이런 방식으로 싱크를 맞춤
또 테스트가 끝나서 캐시가 됐는지 알수 있어야 하니까
헤더에다가 x-cached: hit를 추가
또 문제가 있음
제꺼에서는 잘되잖아요 했는데 남의 거에서 안될수 있음
그래서 테스트를 빡세게 해야함
N-Grinder
Jmeter
Ab test
ngrinder는 익숙하고 회사에서 전사적으로 사용하고 간편한 설정
쉬운 환경 구성, 스크립트 관리 가능(근데 스크립트 관리가 svn임)
그러나 문제가 있음
호나 쓰지 못함. 다른 사람이 사용하고 있다면 줄을 서야함
Worker 영향이 큼
-일종의 자바로 만든 에이전트 들인데 tps가 정확하지 않음
Local 실행이 못함. 근성있다면 도커로 다만들어서 할수 있으나
구성이 복잡함
그래서 locust 사용함
python으로 매우 쉬움
시나리오 테스트 가능
k8s와 환상의 궁함
이론상 무제한 트래픽 가능
local에서 손쉬운 실행
스타트 할때 뭔가 헤더나 인증 설정할 수 있고
테스크 단위로 돌아가는데 테스크로 여러개를 만들 수 있어서 손쉽게
스위칭이 가능함
로컬에서 되게 손쉽게 테스트 가능함
맥북 m1에어기준으로 한 25개-50 까지 워커 만들어서 테스트해도 괜찮은듯
Grinder는 tps단위인데 얘는 rts단위로 나옴
그래서 rts만 보지 않고 response 타임도 같이 봐야 함
이론상으로 무제한으로 쉽게 트래픽을 발생시켜 테스트해볼 수 있는 방식
50개로 테스트 했는데 이이상 늘리면 담당자한테 연락올 것 같아서 여기까지만
테스트 함
한가지 더 필수 툴이 있는데
APM이 필요함
php아니고
Application Performance Managerment
핀포인트를 많이 씀
성능테스트 할때 핀포인트를 같이 써주는게 좋음
성능테스트에 임하는 자세
Locust, pinpoint 서버 상태
맥북에서는 로그를 찍으면서
아래는 해당 파드의 상태
운영에 적용후 성과를 보고하는 자리에서
미친 짓을 계속하다보면 한두개는 걸림
성능테스트는 왜 해야할까?
지옥에서 온 CTO분
이규원
누구나 그럴싸한 아키텍처를 가지고 있다 높은 트래피에 쳐맞기 전까지는
동일한 기능 요구사항에도 서비스 트래픽이 높아지면 수많은 가정이 뒤틀린다.
우아하게 동작하던 기능들은 숨겨놓은 오류들을 쏟아낸다.
여러분이 만든 아키텍처는 로컬에서 수십번을 눌러봐야 문제가 없음
우리의 그 문제는 높은 트래픽을 쳐맞아야 나옴
그래서 우리는 성능 나올때까지 테스트를 해야함
이로직이 되게 간단하게 추상화해서 나온 거임
사실 되게 복잡함
이 아키텍처를 구성할때까지 수십번의 테스트와 밤을 지새고
아 이러면 해결될것 같애 하고 번쩍 일어나서 해결하고 그런게 한두번이 아니었음
한대한대당 cpu가 max를 찍을때까지 tps를 몇을 처리할 수 있을까를
계속 반복고민하면서 계속 반복적인 테스트를 돌려왔고요
tps를 올리고 올릴때마다 그 쾌감은 이루말할 수 없을 것 같습니다
개발자는 어떤 직업이라고 생각하지나요?
저는 개발자는 길을 찾는 직업이라고 생각해요
대용량 트래픽 대응이라는 미션이 떨어졌을때
아 어떻게 하지 고민을 많이하다가
시스템 모니터링을 하고 있었는데
자바 힙 사용량 그래프거든요?
근데 이게 항상 놀아. 그래서 이걸 좀 활용할 수 없을까? 라는 생각에서
시작된게 이 프로젝트
캐시는 아까 말씀드린 바와 같이 로컬 캐시가 제일 빠르죠
싱크가 문제가 될뿐
그래서 이거를 만들었는데
이거 뿐 아니라 고민을, 생각을 녹여내서 만든게 cell platform
'Spring' 카테고리의 다른 글
| ATDD 1주차 (0) | 2024.07.04 |
|---|---|
| Next Step 학습테스트를 통한 스프링 2주차 (0) | 2024.06.18 |
| maven 정리 (3) (0) | 2023.02.05 |
| maven 정리 (2) (0) | 2023.02.05 |
| maven 정리 (0) | 2023.02.04 |